データベースと連動した各種Webサイト構築。モバイル・携帯サイトも対応。3キャリアの公式サイト実績あり。 |
|
|
一人ではすべての技術をカバーしきれない時代。いろいろな分野のスペシャリストが ノウハウを活かしてコラボレーション・チームとして業務を請け負います。 |
|
 |
||
|
|
正規化について
正規化とは、データの矛盾や無駄(重複など)を無くし、シンプルな構造にすることです。 <正規化のメリット>
1.データ管理が容易になる
データに変更が必要な場合、無駄を排除しているため最小限の修正(編集)で済みます。 2.データの共通性 正規化されたデータは、複数のシステムからも利用しやすくなります。またデータ移行もスムーズに行えます。 3.データ容量の削減 無駄な項目を削除するためディスク領域などの消費量を削減できます。データ処理の効率も良くなります。
<正規化のデメリット>
正規化ばかり意識し過ぎると「検索の内容」によっては、パフォーマンスが低下する可能性もあります。
データ検索・データ更新の頻度やリレーションの階層などと、実際の業務バランスを見て正規化は行いましょう。 場合によっては意図的に正規化を行わず性能を向上させる設計も必要です。 第一正規化
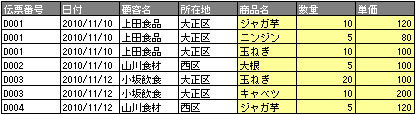
■非正規データ

第二正規化
第三正規化
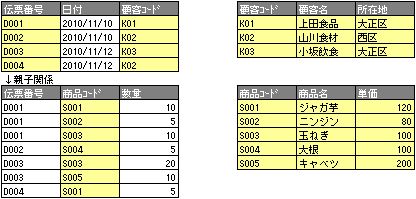
■■第三正規化(推移的関数従属関係の排除)
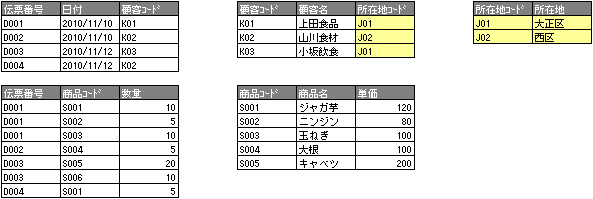 付加情報の中で重複するようなデータをさらに分割する。
|
|
|
| Copyright(C) 1997-2010, FELLOW-SHIP. All Rights Reserved. |